公司最近一直在迁移项目部署到阿里云的k8s,某天一早来到公司后,熟练的克隆了一个Node项目的部署配置,准备开始迁移老项目。测试环境(qa环境)发布正常后,满心欢喜的开始部署到预发布环境(yz环境),然而发布才过了几分钟,就发现pm2报错:
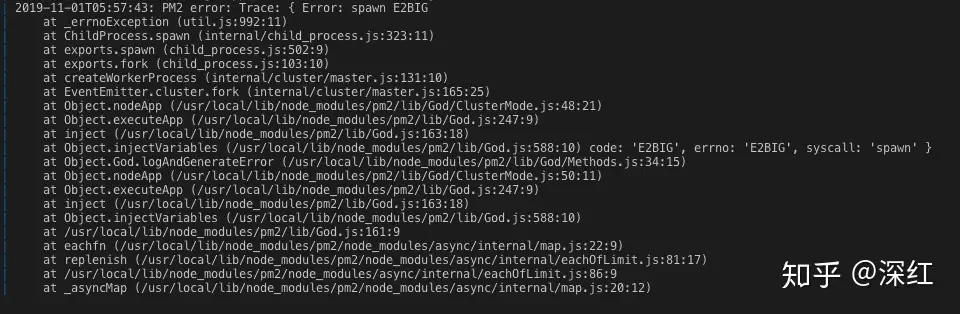
PM2 error: Trace: { Error: spawn E2BIG 这个报错以前从来没有见过,网上搜索以后,发现大多数回答都在说环境变量过多导致的。然而qa环境和yz环境是一样的dockerfile启动配置,为啥qa环境却可以正常启动?
为了排除是自己配置写错的原因,我重启了一个已经成功迁移的项目,然而预发布环境同样开始报错,这下炸了锅,所有以前迁移的项目,yz环境都发布不了!
发现事情的严重性后,迅速问了运维部门的人是否更改过yz环境,然而回答是没动过环境。
问题排查
既然网上说是环境变量过多导致,于是想登入yz环境的容器内部看看。但是因为pm2无法启动成功,所以docker一直在尝试重启容器,没办法直接进入容器。
于是决定先去qa环境的容器里看看。进入容器后,输入printenv | wc -l,发现环境变量的确非常多,竟然有1300多个环境变量!
printenv打印出详细信息:
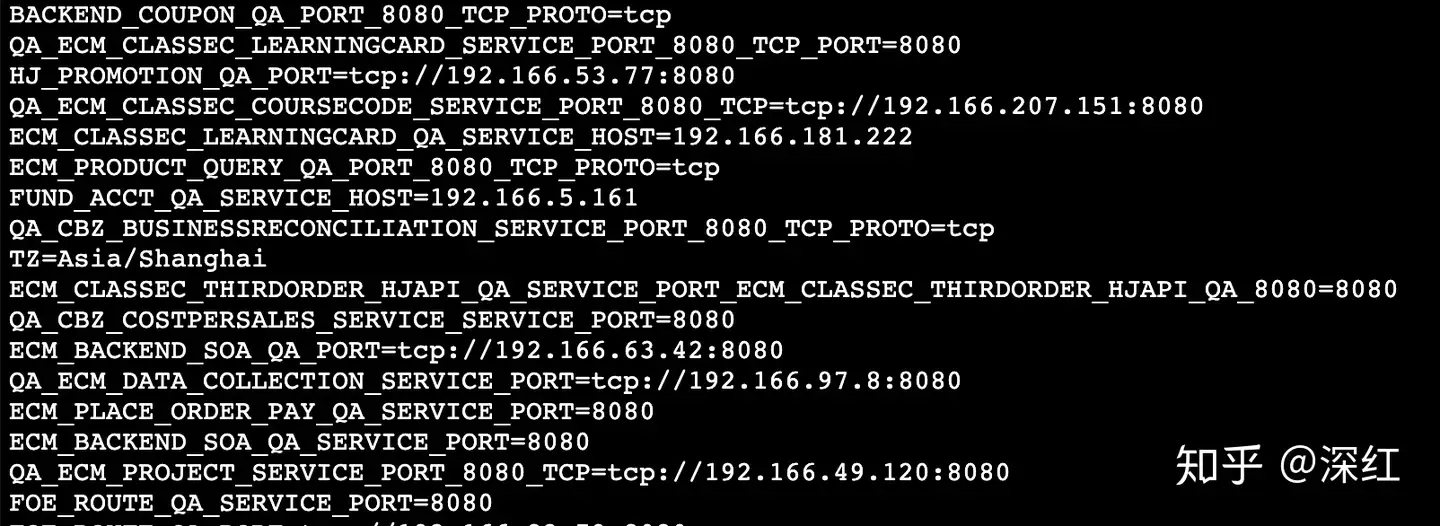
这些变量看得我一脸懵逼,都是些部门的Java项目名称。问了下运维部门的同学,因为公司用的是Wayne这个开源的k8s管理平台,它会把某个命名空间下所有项目的k8s配置,以环境变量的形式注入到容器里。
也就是说,我的node项目和java项目因为放在了一个命名空间下,所以90多个java项目的配置也被注入到了我的容器里,随着java项目部署的越来越多,我容器里的环境变量也越变越大,直到今天,终于引发了pm2的报错。
然而为啥qa环境下pm2没有报错呢?仔细对比了下qa和yz环境下pm2的启动脚本,发现是因为:
yz环境下使用的是pm2的cluster模式,源码里这句:
clu = cluster.fork({pm2_env: JSON.stringify(env_copy), windowsHide: true});
会把当前的环境变量复制一份给子进程,然而环境变量太大,于是报错!
解决方案
1.要求运维同学优化部署方式,不要注入项目以外的其他环境变量。不过运维同学说是k8s的机制,咋也不懂,也不敢问。
2.不使用pm2的cluster模式,只用fork模式。如果仍要坚持使用cluster模式,则先运行一段shell脚本,剔除不需要的环境变量。
# 遍历所有环境变量,删除匹配正则的环境变量
for i in `env | grep -E -i 'ECM_QA_|ECM_YZ_|ECM_PROD_' | sed 's/=.*//'` ; do
unset $i
done
# Docker中使用pm2-runtime命令
pm2-runtime start app.json在这里,我把环境变量包含ECM_QA_ ECM_YZ_ ECM_PPOD_的全部删除。当然你也可以选择修改pm2的源码,比如这个解决方法,不过并不推荐。
3.也许你并不需要PM2!
k8s下的Node部署
老项目当时选择PM2的启动方式,是因为PM2可以后台运行Node项目,并且cluster模式可以很方便的利用多核性能。然而这次迁移使用了k8s方案,其实可以完全抛弃之前的启动方式。
在Docker中,我们需要保证pid为1的进程一直运行,因此使用PM2时,需要使用pm2-runtime命令,保证不会自动退出。如果使用原生方式,直接node app.js,反而更加简单。
Node是单线程的,为了充分利用多核cpu性能,才使用了cluster模式创建子进程。然而Docker的理念是一个容器一个进程,我们可以创建多个pod,把集群的调度交给k8s来管理。
因此,使用k8s的方案下,我们完全可以直接node app.js启动。重启应用和集群调度,全都交给k8s来做。
总结
在这次事故中,发现自己对于Linux,Docker的部署知识相当匮乏,Linux的一些常用命令也十分陌生。虽然前端工程师平时接触到这些方面有限,但是如果完全不懂,遇到线上事故,真的只能干瞪眼了。

 Serverless For Frontend 前世今生
Serverless For Frontend 前世今生 快速定位线上 Node.js 内存泄漏问题
快速定位线上 Node.js 内存泄漏问题 深入理解Node.js 进程与线程(8000长文)
深入理解Node.js 进程与线程(8000长文) V8 内存管理和垃圾回收机制总结
V8 内存管理和垃圾回收机制总结



